6. Storage 📦
Storage is core to every stage—data is stored repeatedly across ingestion, transformation, and serving.
Two things to consider while deciding on storage are:
- Use case of the data.
- The way you will retrieve it.
The way storage is explained in the book is with the following figure:
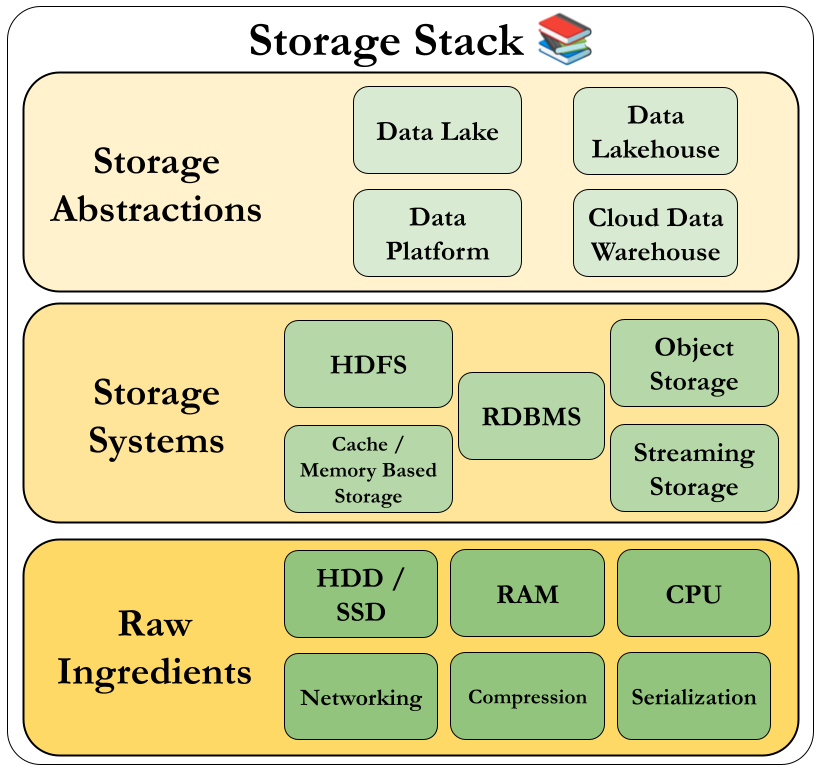
Raw Ingredients of Data Storage
Here are some one liners as definitions.
-
Magnetic Disk Drive – Traditional, cost-effective storage with moving parts; slower read/write.
-
Solid-State Drive (SSD) – Faster, durable storage with no moving parts.
-
Random Access Memory (RAM) – Temporary, ultra-fast memory used during active processing.
-
Networking and CPU – Key hardware for moving and processing data efficiently.
-
Serialization – Converts data into storable/transmittable formats.
-
Compression – Reduces data size for faster storage and transfer.
-
Caching – Stores frequently accessed data for quick retrieval.
Data Storage Systems
Operate above raw hardware—like disks—using platforms such as cloud object stores or HDFS. Higher abstractions include data lakes and lakehouses.
Here are some one liners about them.
-
Single Machine vs. Distributed Storage – Single-node is simple; distributed scales across machines for reliability and size.
-
Eventual vs. Strong Consistency – Eventual allows delay in syncing; strong guarantees immediate consistency.
-
File Storage – Stores data as files in directories; easy to use, widely supported.
-
Block Storage – Breaks data into blocks for fast, low-level access; used in databases and VMs.
-
Object Storage – Stores data as objects with metadata; ideal for large-scale, unstructured data.
-
Cache and Memory-Based Storage Systems – Keep hot data in fast memory for quick access.
-
The Hadoop Distributed File System (HDFS) – Distributed storage system for big data, fault-tolerant and scalable.
-
Streaming Storage – Handles continuous data flows; used for real-time analytics and pipelines.
-
Indexes, Partitioning, and Clustering – Techniques to speed up queries and organize large datasets.
Data Engineering Storage Abstractions
These are the abstractions that are built on top of storage systems.
Let's remember our map for storage.
Here are some of the Storage Abstractions.
-
The Data Warehouse – Data warehouses are a common OLAP architecture used to centralize analytics data. Once built on traditional databases, modern warehouses now rely on scalable cloud platforms like Google's BigQuery. It's a structured, query-optimized for analytics and BI workloads.
-
The Data Lake – Stores raw, unstructured data at scale for flexibility. Funnily enough, someone referred to a Data Lake as just files on S3.
-
The Data Lakehouse – Combines warehouse performance with lake flexibility in one system. This means incremental updates and deletes on schema managed tables.
-
Data Platforms – Unified environments managing storage, compute, and processing tools. Vendors are using this term as a singular place to solve problems.
-
Stream-to-Batch Storage Architecture – Buffers real-time data for batch-style processing later. Just like Lambda architecture, streaming data is sent to multiple consumers—some process it in real time for stats, while others store it for batch queries and long-term retention.
Big Ideas in Data Storage
Here are some big ideas in Storage.
🔍 Data Catalogs
Data catalogs are centralized metadata hubs that let users search, explore, and describe datasets.
They support:
-
Automated metadata scanning
-
Human-friendly interfaces
-
Integration with pipelines and data platforms
🔗 Data Sharing
Cloud platforms enable secure sharing of data across teams or organizations.
⚠️ This requires strong access controls to avoid accidental exposure.
🧱 Schema Management
Understanding structure is essential:
-
Schema-on-write: Enforces structure at ingestion; reliable and consistent.
-
Schema-on-read: Parses structure during query; flexible but fragile.
💡 Use formats like Parquet for built-in schema support. Avoid raw CSV.
⚙️ Separation of Compute & Storage
Modern systems decouple compute from storage for better scalability and cost control.
- Compute is ephemeral (runs only when needed).
- Object storage ensures durability and availability.
- Hybrid setups combine performance + flexibility.
🔁 Hybrid Storage Examples
- Amazon EMR: Uses HDFS + S3 for speed and durability.
- Apache Spark: Combines memory and local disk when needed.
- Apache Druid: SSD for speed, object storage for backup.
- BigQuery: Optimizes access via hybrid object storage.
📎 Zero-Copy Cloning
Clone data without duplicating it (e.g., Snowflake, BigQuery).
⚠️ Deleting original files may affect clones — know the limits.
📈 Data Storage Lifecycle & Retention
We talked about the temperature of data. Let's see an example.
🔥 Hot, 🟠 Warm, 🧊 Cold Data
| Type | Frequency | Storage | Cost | Use Case |
|---|---|---|---|---|
| Hot | Frequent | RAM/SSD | High | Recommendations, live queries |
| Warm | Occasional | S3 IA | Medium | Monthly reports, staging data |
| Cold | Rare/Archive | Glacier | Low | Compliance, backups |
Use lifecycle policies to move data between tiers automatically.
⏳ Retention Strategy
- Keep only what's valuable.
- Set Time-to-Live (TTL) on cache or memory.
- Consider regulatory needs (e.g., HIPAA, GDPR).
- Use cost-aware deletion or archival rules.
🏢 Single-Tenant vs Multitenant Storage
Single-Tenant
- Each tenant/customer has isolated resources and databases.
- Pros: Better privacy, schema flexibility.
- Cons: Harder to manage at scale.
Multitenant
- Tenants share the same database or tables.
- Pros: More efficient resource usage.
- Cons: Requires careful access control and query design.
Summary 😌
Storage is the backbone of the data engineering lifecycle—powering ingestion, transformation, and serving. As data flows through systems, it's stored multiple times across various layers, so understanding how, where, and why we store data is critical.
Smart storage decisions—paired with good schema design, lifecycle management, and collaboration—can drastically improve scalability, performance, and cost-efficiency in any data platform.
Here are 3 strong quotes from the book.
As always, exercise the principle of least privilege. Don’t give full database access to anyone unless required.
Data engineers must monitor storage in a variety of ways. This includes monitoring infrastructure storage components, object storage and other “serverless” systems.
Orchestration is highly entangled with storage. Storage allows data to flow through pipelines, and orchestration is the pump.
🡐 Part 2 Overview